
ドメインやURL正規化の方法(リダイレクトやcanonicalカノニカル設定)と期待できるSEO効果を解説

同じ内容のページでもURLが違っていたり、スマートフォンサイトとパソコンサイトでURLが違っていたりするときはURLを正規化する必要があります。URL正規化をおこなわない場合、重複コンテンツとして検索エンジンからペナルティが課される恐れがあり、SEOにも悪影響を及ぼします。
 URL正規化は301リダイレクトかcanonicalタグを使っておこないます。この記事では正規化する理由と方法、正規化すべきURLについて解説しています。また、正規化できているか確認する方法や注意点にもふれています。
URL正規化は301リダイレクトかcanonicalタグを使っておこないます。この記事では正規化する理由と方法、正規化すべきURLについて解説しています。また、正規化できているか確認する方法や注意点にもふれています。

URL正規化とは
URL正規化とは同じ内容のページが違うURLで複数存在するとき、1つのURLに統一することをいいます。URLを統一することで、検索エンジンからの評価を1つのURLに集中させることができるため、SEO対策としておこなうべき重要な要素です。
URL正規化ができていない場合は検索エンジンから重複コンテンツとみなされ、検索結果に表示されなくなる恐れがあります。
正規化をおこなうべきURL
URL正規化の際にチェックすべき項目は6つあります。自社サイトのURLに該当するものがあれば、正規化してください。
- 大文字と小文字の違い
- wwwの有無
- .htmと.htmlの違い
- httpとhttpsの違い
- パラメーターの有無
- トレイリングスラッシュの有無
大文字と小文字が違う
| https://sample.com/Sample
https://sample.com/sample |
URLは大文字を使わず、すべて小文字にすべきです。大文字を使っている場合は小文字のURLに正規化してください。
www.の有無
| https://www.sample.com/sample
https://sample.com/sample |
wwwはあってもなくても構いませんが、ないほうがすっきりしてみえるほか覚えやすいメリットがあります。
.htmと.htmlの違い
| https://sample.com/index.htm
https://sample.com/index.html |
htmはhtmlを略したものにすぎず、どちらもHTMLファイルです。ただし、同一の内容をそれぞれの拡張子で公開すると、重複コンテンツと判断されることがあります。必ずどちらかに統一してください。
httpとhttpsの違い
| http://sample.com/
https://sample/sample.com |
httpとhttpsは、簡単に言えば通信の内容を暗号化しているかいないかです。httpsは通信の内容を暗号化しているため、なりすましを防ぐメリットがあります。
Googleもhttpsの使用を推奨していますが、httpと混在していると重複コンテンツとみなされることがあり、httpsに統一する必要があります。
パラメーターの有無
| https://sample.com
https://sample.cpm/?gclid=ABCD |
パラメーターとはURLのあとに?(クエスチョン)から始まる変数です。広告のアクセス解析やECサイトなどに使われています。基本的にはパラメーターのないURLに正規化しますが、どうしても必要なときはcanonicalタグを使用してください。
トレイリングスラッシュの有無
トレイリングスラッシュとは、URLの末尾につく/(スラッシュ)のことです。
| https://sample.com/media/
https://sample.com/media |
トレイリングスラッシュがあるときはmediaというディレクトリ内のindex.htmやindex.phpなどを表示し、ないときはmedia.htmというファイルを表示します。ただしmedia.htmファイルがなければ、一般的に/media/と同じ内容を表示します。
このようにトレイリングスラッシュの有無によって処理の仕方が違うため、URLを正規化してください。
URLがドメイン名のみの場合(https://sample.com)、トレイリングスラッシュの有無にこだわる必要はありません。なぜならトレイリングスラッシュのないURLを表示させるときでも、ブラウザやGooglebotはトレイリングスラッシュありの状態で処理しているからです。
URL正規化をおこなう理由
URLを正規化する理由は主に3つあります。
- 検索エンジンの評価分散を防ぐ
- クローラビリティの向上
- トラッキング分析のコストダウン
これらの理由で正規化すると、結果的にSEO効果も期待できます。
検索エンジンの評価分散を防ぐ
検索エンジンから重複コンテンツと判断されたり、同一の内容でも2つのページが存在していると被リンクが分散されたりします。結果的に検索エンジンからの評価が分散するため、SEO的にも効率的とはいえません。
これについてはGoogleが公式に発信しています。
ある1つのコンテンツに対して、張られるリンクのURLがユーザーによって異なると、そのコンテンツに対する評価がURLごとに分かれてしまう恐れがあります。これを防ぐために、サイト内でページをリンクするときには、常に特定のURLを使用するようにしましょう。
出典:1つのページにURLは1つにしよう(Google検索エンジン最適化スターターガイド)
クローラビリティの向上
クロールとは、インターネット上でクローラーというロボットが情報収集することをいいます。クローラーが収集した情報をもとに、検索結果にページを表示させています。ですが、何千、何億ものページがWEBで公開されているなか、すべてが検索結果に表示されているわけではありません。
どれだけ良質なコンテンツを公開していても、クローラーに情報を拾ってもらえなければ意味がないのです。クローラビリティの向上とはクローラーに情報を提供して自社サイトを認識してもらうことともいえ、SEO対策につながっています。
URL正規化をおこなうと、クローラーにページを見つけてもらいやすくなります。これによって自社サイトをユーザーの目にとまりやすくしたり、ページを更新したときに検索結果に早く反映させたりできます。
正規化されていないURLは、クローラーにとって深海で宝石をさがすようなものです。かならずURLを正規化して、クローラーに適切な情報を提供できるようにしてください。
トラッキング分析のコストダウン
自社サイトをトラッキング分析するときに重複ページが存在すると、2度分析をおこなうことになります。結果的に時間や手間がかかり、コストパフォーマンスの低下を招きます。このリスクを回避するためにもURLを正規化してください。
URL正規化の注意点
URLの正規化をおこなうとき、事前に覚えておきたいポイントが3つあります。
- 正規化には時間がかかる
- 正規化するURLを確認する
- robots.txtは使わない
正規化には時間がかかる
URLを正規化したといっても、すぐにGoogleが認識するわけではありません。URL正規化をしたあと、クローラーが情報を収集して検索結果に表示されるようになるまでは1〜6か月ほどかかるといわれています。
ただし、Google Search Consoleからインデックス登録をリクエストすると検索結果に表示されやすくなります。リクエストするときはURL検査を選択して「インデックス登録をリクエスト」をクリックして実行してください。
この方法はあくまでGoogleにリクエストする行為であり、必ずしも検索結果に早く表示されると保証されているわけではありません。
正規化するURLを確認する
URLを正規化するときは、URLを確認してからおこなってください。クローラーに提供したいページのURLを間違えると、404エラーや重複ページを正規化する事態を招きます。
事前に正規化するURLをリストアップしておいて、あわせて誤字脱字がないかを確認しておくと問題は解消できます。
robots.txtは使わない
robots.txtを使って重複コンテンツをクローラーに認識させないことで、正規化を図るケースがあります。ですが、Googleはこの方法を推奨していません。これはクローラーが重複しているページの内容を確認して、Google自身で是非を判断したいという考えに基づいています。
SEO対策としてURLを正規化するときは、重複コンテンツを隠すのではなく正しい内容でコンテンツを作ることを念頭に置いてください。
URL正規化の方法
URL正規化の方法は2つあります。
- 301リダイレクト
- canonicalタグを使う
301リダイレクトは古いページを新しいページに統合、もしくはサーバー移転したときにおこないます。canonicalタグは、ページ内容が似ていてもそれぞれに特徴があるため、検索エンジンに重複コンテンツと認識させたくないときに使います。
301リダイレクトとcanonicalタグを使うときは、目的に合わせて使い分けてください。
301リダイレクト
サーバー移転やページのアップデートをおこなうと、検索エンジンからの評価は白紙に戻ります。つまり、すでに検索結果で上位に表示されていたページが検索結果に表示されなくなるリスクを秘めています。これを回避できるのが301リダイレクトです。
手順は次のとおりです。
- htaccessファイルを作成
- 文字コードをUTF8にする
- 状況に合わせて記述
- 最後に空白行を作って保存
- サーバーにアップロード
- 「htaccess」を「.htaccess」に変更
301リダイレクトを使う場合、利用しているサーバーが.htaccessに対応しているかを確認してください。
.htaccessファイルはテキストエディタで作成します。テキストコードはUTF8にしてください。使っているパソコンがwindowsの場合、保存するときはファイル名を「htaccess」にして、ファイルの種類を「すべてのファイル」にしてから保存します。
また、ファイル名に.(ドット)をつけるのはサーバーへアップロードしてからにしてください。これはパソコンの環境によっては、.(ドット)から始まるファイルを作成できないことがあるため、対策としておこないます。
www.のあるURLをなしにして正規化する場合
| RewriteEngine on
RewriteCond %{HTTP_HOST} ^www\.sample\.com$ RewriteRule ^(.*)$ http://sample.com/$1 [R=301,L] |
index.htmlのあるURLをなしにして正規化する場合
index.htmlの有無については、index.htmlのないURLをリダイレクト先として指定してください。現在、index.htmlのないURLが一般的であることと、ユーザーが覚えやすいことがメリットとされているためです。
| RewriteEngine on
RewriteCond %{THE_REQUEST} ^.*/index.(html|htm|php) RewriteRule ^index.(html|htm|php)$ https://sample.com/$1 [R=301,L] |
httpのあるURLをhttpsにして正規化する場合
| RewriteEngine on
RewriteCond %{HTTPS} off RewriteRule ^(.*)$ https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L] |
httpsリダイレクトをしたときは、一時的に検索順位が下がることがあります。1〜2週間ほどで元に戻りますが、必ず順位の推移を確認してください。引き継ぎが正常におこなわれていれば順位はもとに戻ります。また、ほかの事例でも正規化が正しくできているかをチェックしてください。
canonicalタグを使う
canonical(カノニカル)タグとは、似た内容のコンテンツであっても重複コンテンツと判断されないように検索エンジンに宣言するタグです。使い方は2つあります。
- HTMLのheadタグ内に記述
- httpヘッダーに指定する
前者は一般的なWEBサイトに適していて、後者はpdfファイルや他のファイル形式にも使用できますが.htaccessを使うため、事前にサーバーが対応しているかを確認してください。
canonicalタグを使うときのポイントは、このタグはあくまでGoogleへ宣言する役割を果たすだけという点です。実際の判断はGoogleにゆだねられるので、必ずしも重複コンテンツと認識されなくなるというわけではありません。
また、headタグ内に使うcanonicalタグは1つだけです。2つ以上使うと検索エンジンがどちらのcanonicalタグを優先すべきか判断できなくなります。
さらに、1つのコンテンツを複数ページにわたって展開しているとき、1ページ目にcanonicalタグを使うとそれ以降のページが検索結果に表示されなくなります。このようなページに対してcanonicalタグを使用するのは控えてください。
HTMLのheadタグ内に記述
HTMLのheadタグ内に統一したいURLをまじえて、canonicalタグを記述します。head以外の場所に記述した場合、効果はありません。記述するときは、統一するURLと重複しているURLのHTML両方におこなってください。
例えば、https://www.sample.comのwwwをなしにするには次のように設定します。
| <head>
・ <link rel=”canonical” href=”https://sample.com”> ・ </head> |
https://www.sample.com/のトレイリングスラッシュをなしにするときは次にように設定してください。
| <head>
・ <link rel=”canonical” href=”https://www.sample.com”> ・ </head> |
URLを記述するときはスペルミスがないかを確認してください。
httpヘッダーに指定する
httpヘッダーにcanonicalタグを使うと、HTML以外のファイル形式にも対応できます。方法はGoogleが公式に発信しています。
では実際に、rel=”canonical” を指定した HTTP ヘッダーがどのような働きをするか、HTML ページ版と PDF ダウンロード版の両方で文書を提供しているウェブサイトを例に見ていきましょう。HTML 版と PDF 版の URL はそれぞれ下記のとおりとします。
http://www.example.com/white-paper.html
http://www.example.com/white-paper.pdf
このケースでは、PDF ファイルが要求されたときに rel=”canonical” HTTP ヘッダーを使用することによって、優先する URL が上記 HTML 文書であることを Google に通知することができます。
記述例:
GET /white-paper.pdf HTTP/1.1
Host: www.example.com
(…以下、他の HTTP リクエスト ヘッダー…)
HTTP/1.1 200 OK
Content-Type: application/pdf
Link: <http://www.example.com/white-paper.html>; rel=”canonical”
Content-Length: 785710
(…以下、他の HTTP レスポンス
ヘッダー…)
出典:HTTP ヘッダーでの rel=”canonical” 属性に対応しました(Google検索セントラル)
この方法を実行するときは、ディベロッパーツールを使います。
alternateタグを使う
内容が同じでもパソコンサイトとスマートフォンサイトでURLが違っていたり、他言語版サイトを用意していたりすると、検索結果が重複コンテンツと判断することがあります。この事態を未然に防ぐために、alternateタグを使ってください。
alternateタグはcanonicalタグとセットで使います。
今回はパソコンサイトとスマートフォンサイトのURLを仮定します。
- パソコンサイトURL https://sample.com
- スマートフォンサイトURL https://sp.sample.com
パソコンサイトのheadタグ内は次のようにしてください。
| <link rel=”alternate” media=”only screen and (max-width: 768px)” href=”https://sp.sample.com” /> |
同時にスマートフォンサイトのheadタグ内は次のようにする必要があります。
| <link rel=”canonical” href=”https://sample.com” /> |
タグを記述するときはPCサイトにスマートフォンサイトのURLを入れ、スマートフォンサイトにパソコンサイトのURLを入れておこないます。
alternateタグはスマートフォンサイト用にURLが存在しているときに活用できますが、記述ミスがあると検索結果に表示されなくなるリスクがあります。レスポンシブデザインのサイトに変更すると、このリスクから解放されます。
URL正規化の確認方法
URL正規化が正確におこなわれているかを確認するときはGoogle Search Consoleを使います。URLを調べるときは3つのステップを踏んで確認します。
- Google Search Consoleにログイン
- メニューからURL検査を選択
- 検査するURLを入力
- カバレッジを確認する
まずはGoogle Search Consoleにログインしてください。
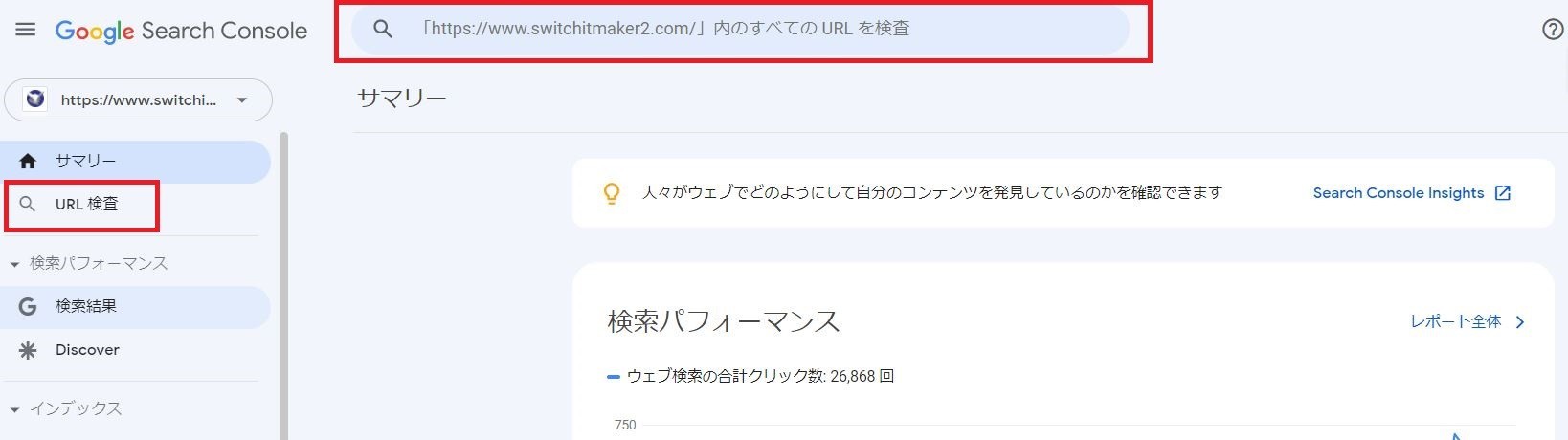
メニューからURL検査を選択して、自社サイトで検査したいURLを入力します。
301リダイレクトをおこなったとき、表示された結果のなかで確認するポイントが3つあります。
- カバレッジ欄に「ページにリダイレクトがあります」と表示されている
- ユーザーが指定した正規URL
- Googleが選択した正規URL
301リダイレクトで正規化ができていれば、Googleが選択した正規URLの欄に「ユーザーが指定した正規URLと同じ」と出ています。canonicalタグを使っている場合も基本的には同じですが、確認する3つのポイントのうち、カバレッジ欄の内容が違います。
- カバレッジ欄に「代替ページ(適切なcanonicalタグあり)」と表示されている
- ユーザーが指定した正規URL
- Googleが選択した正規URL
カバレッジ欄に代替ページ(適切なcanonicalタグあり)と、出ているかを見てください。また、canonicalタグで正規化できていればGoogleが選択した正規URL欄に「ユーザーが指定した正規URLと同じ」と出ています。
URL検査をおこなって、このように表示されていなければ正規化ができていません。.htaccessファイルやcanonicalタグ内のURLが間違っていないかを確認してください。
まとめ
URL正規化とは、内容が同じでもURLが異なるページを1つのURLに統一することです。正規化をおこなうことで、検索エンジンから重複コンテンツと判断されるリスクを回避できます。URLを正規化すると検索エンジンからの評価の分散を防ぐほか、クローラビリティが向上します。また、サイトのトラッキング分析をするときのコストダウンも実現します。URL正規化は.htaccessを使った301リダイレクトと、canonicalタグを使う2種類の方法があります。ただし、301リダイレクトはサーバーが.htaccessに対応していなければ使えません。スマートフォンサイトとパソコンサイトでURLが異なるときは、canonicalタグと一緒にalternateタグを使って正規化してください。注意点として正規化には時間がかかること、URLの記述ミスがないように確認すること、robots.txtは使わないことを覚えておいてください。

この記事の監修者

日本大学法学部卒業、広告代理店で12年間働いている間、SEOと出会い、SEO草創期からSEO研究を始める。SEOを独学で研究し100以上のサイトで実験と検証を繰り返しました。そのノウハウを元に起業し現在、11期目。営業、SEOコンサル、WEB解析(Googleアナリティクス個人認定資格GAIQ保持)コーディング、サイト制作となんでもこなす。会社としては今まで2000以上のサイトのSEO対策を手掛けてきました。


















