
robots.txtとは?設定する目的や具体的な書き方を解説

WEB担当者であればrobots.txtという言葉を聞いたことがあるのではないでしょうか。
これは検索エンジンのクローラーに、どのページをクロールしてもらい、どのページをクロールしないで欲しいかを指示するためのファイルです。
robots.txtを適切に設定することで、検索エンジン最適化(SEO)に役立ち、WEBサイトのインデックスを効果的に進めることができます。
 そこでここでは、robots.txtの設定の目的や具体的な書き方について解説します。
そこでここでは、robots.txtの設定の目的や具体的な書き方について解説します。


robots.txtとは?
robots.txtとは、特定のコンテンツへのクロールを拒否するためのファイルを指します。
そもそもクロールとは、検索エンジンのクローラーと呼ばれるロボットがインターネット上のサイトを巡回することをいい、サイトの情報を集めるためには欠かせない仕組みです。クロールによって集まった情報は、その後検索エンジンのデータページへと保存されます。
一般的にサイトのなかには、重要なコンテンツとそれほど重要ではないコンテンツが存在するはずです。そのためrobots.txtによって一部のクロールを制御し、重要なコンテンツへとクロールを集中させることが可能となります。
robots.txtの歴史
robots.txtは1994年にWebCrawlerという検索エンジンで働いていた Martijn Koster が考案しました。当初はWEBサイト運営者がクローラーのアクセスを制御する手段として提供されています。
その後、1997年にはRobots Exclusion Standard(ロボットスタートエクスクルードスタンダード。通称:Robots Exclusion Protocol)という仕様が策定され、robots.txtがより一般的に使用されるようになりました。
現在ではこの仕様に基づいて、WEBサイト運営者はクローラーにどのページをクロール拒否するかを指示することができるようになり、WEBサイト運営者にとって欠かせないツールとなっています。
参考ページ:Wikipedia
noindexとの違い
robots.txtと間違えやすい設定が、noindexを活用した方法です。noindexは検索エンジンにインデックス(データページへ情報を保存)させないための設定となり、HTMLコードにmetaタグを記述する仕組みとなります。
そのため以下のように、目的や設定方法には大きな違いがあります。
| 項目 | robots.txt | noindex |
| 形式 | テキストファイル | meta要素またはHTTPヘッダ |
| 対象 | サイト全体に設定可能 | 個別ページで設定 |
| 目的 | クロールを拒否 | インデックスを拒否 |
またnoindexではインデックスを拒否するため、検索結果に表示されることはありません。しかしrobots.txtではクロールを拒否する設定となり、検索結果に表示される可能性はあると認識してください。
robots.txtの目的
robots.txtの主な目的はクロールを拒否することですが、他にもクローラービリティの最適化やXMLサイトマップの送信など、さまざまな役割をもちます。またHTMLでなければ使用できないnoindexの代替として、robots.txtの活用は欠かせない要素といえます。
ここでは、robots.txtの目的について詳しく解説していきます。
特定のページをクロールさせない
robots.txtの最大の目的は特定のコンテンツでクロールを拒否することですが、コンテンツではページ単位やディレクトリ単位など、さまざまな階層で設定可能です。
例えば、以下のようなコンテンツが存在する場合に活用できます。
- 未完成のページ
- ログインが必須のページ
- 会員様にしか公開していないページ
このようなページがある場合、検索結果に表示させたくないことや、SEOをまったく意識していないことが多いといえます。不要なコンテンツのクロールは、SEOにおいて逆効果となる可能性があります。
そのためrobots.txtを活用しクロールを拒否することで、無駄にサイト評価を下げるような事態を未然に防ぐことが可能となります。
画像や動画ファイルをクロールさせない
サイトを運営するうえで画像や動画を活用する機会は多いですが、画像、動画ファイルはHTMLではないため、ページにnoindexの設定はできません。
しかしrobots.txtであれば、HTMLではないファイルについてもクロールの拒否設定が可能です。そのためnoindexが使用できない際の代替案として活用される機会も多いといえます。
ただし使用しているサイトによっては画像ページが自動生成されることや別途作成できる場合もあり、通常ページと同様にnoindexを活用できるパターンもあります。
クローラビリティの最適化
robots.txtは重要なコンテンツへクロールを促せるため、クローラビリティの最適化にもつながります。
コンテンツ量の少ないサイトでは問題となりませんが、ECサイトのように大量のページが存在する場合、クローラーはすべてのページをクロールできるとは限りません。
なかには重要なページではあるものの、ページ量が原因となりクロールされないといったこともあります。
仮にアクセスの見込めるページや問い合わせにつなげるページなど重要な役割をもつ場合、サイトにとっては大きな痛手となります。
そのためrobots.txtによって無駄なページのクロールを拒否し、重要なページを確実にクロールさせることが効果的です。またrobots.txtによってクロールが最適な状態になれば、サイト全体のクロール頻度が高まることや、クロールの量が増加するなどの効果も得られます。
XMLサイトマップの提示
robots.txtではXMLサイトマップを記載でき、検索エンジンにサイトマップを送信する役割をもちます。Googleであれば「Google Search Console」、Bingであれば「Bingウェブマスターツール」などからサイトマップを送信できますが、検索エンジンのなかにはツールが存在しないこともあります。
そのためクロール状況とサイト構造を効率良く伝える際は、robots.txtは非常に便利な手段といえます。
robots.txtの書き方
robots.txtを設定する際は、決められた項目に沿って該当する内容を入力する仕組みです。記述項目は主に4つあり、具体的なサンプルコードについては「Google検索セントラル」をご確認ください。
ここでは、robots.txtの書き方について解説します。
User-Agent
User-Agentは、制御したいクローラーを指定する際に活用する記述項目です。
記述内容はこちら
- すべてのクローラー:*(アスタリスクマーク)
- Googleのクローラー:Googlebot
- スマートフォン用のクローラー:Googlebot
- AdSenseのクローラー:Mediapartners-Google
- Google画像検索のクローラー:Googlebot-Image
基本の記述方法は、すべてのクローラーを対象とする「*」を入力します。仮にGoogleからのクロールを拒否する場合には、Googleクローラーの「Googlebot」を入力します。
Disallow
Disallowは、クロールを拒否するページやディレクトリを指定する際に活用する記述項目です。URLパスを入力することで、限定的にクロールの拒否設定がおこなえます。
- サイト全体:「Disallow: /」
- ディレクトリの指定:「Disallow: /abc9999/」
- ページの指定:「Disallow: /abc9999.html/」
- 「abc9999」にURLパスを入力
Disallowは活用する場面が多い記述項目となるため、入力内容を覚えておいてください。
Allow
Allowはクロールを許可するための記述項目となり、Disallowとは真逆の役割を持ちます。ただし通常であれば、Allow項目を入力しなくてもクロールは許可された状態です。そのため活用する場面は少ないといえます。
基本的にはDisallowを入力してはいるものの、さらに特定のページやディレクトリのみクロールを許可させる場合にAllowを活用する流れとなります。
具体的には以下のような状態です。
- User-agent: *
- Disallow: /sample/
- Allow: /sample/abc9999.html
上記の場合は「sample」というディレクトリのクロールを許可してはいるが、そのなかでも「abc9999.html」というページのみクロールを許可する記述です。
Sitemap
Sitemapはその名のとおり、サイトマップを送信するために活用する記述項目です。
入力は任意となりますが、Sitemapを入力することでクロールの速度は高まる傾向があります。そのためクローラビリティを向上させたい場合には入力をおすすめします。
記述内容はこちら
- Sitemap:http://abc9999.com/sitemap.xml
- 「abc9999.com」にサイトマップのパスを入力
仮にサイトマップのパスが複数ある場合には、改行して入力してください。
関連記事: サイトマップにSEO効果がある!?実はリスクがあるサイトマップ
robots.txtの設定方法
実際にrobots.txtを設定するためには、以下の方法を実施します。
- プラグインの使用
- 直接アップロード
WordPressサイトを活用している場合には、簡単に設定できるプラグインの使用がおすすめです。ここでは、robots.txtの設定方法について解説していきます。
プラグインの使用
WordPressサイトであれば「All in One SEO Pack」というプラグインを活用することで、簡単にrobots.txtの設定がおこなえます。
以下の方法で設定できます。
- 「All in One SEO Pack」をダウンロードし有効化する
- WordPress管理画面から「投稿」→「Robots.txt」の設定画面を表示させる
- 「機能」のフリーをすべて有効化する
ここまで設定すると「Robots.txtファイルを作成」の最下部に以下が記述されます。
- User-agent: *
- Disallow: /wp/wp-admin/
- Allow: /wp/wp-admin/admin-ajax.php
- Sitemap: https://sample.com/sitemap.xml
あとは前述の「書き方」を参考に編集すれば完了です。
直接アップロード
どのサイトにも共通する方法が、サイトのディレクトリトップに直接アップロードする方法です。
具体的な条件はこちら
- ファイル形式:「UTF-8」エンコードされた書式なしテキスト
- ファイルサイズ:上限500KB
サブドメインは問題ありませんが、サブディレクトリでは検出されないため注意してください。
robots.txtの確認方法
robots.txtの確認ではrobots.txtファイルを直接確認する方法もありますが、見落としや確認ミスが発生する可能性があるため、ツールの活用がおすすめです。「robots.txtテスター」はGoogleが無料提供しているツールとなり、URLを入力するだけで簡単にエラー確認をできます。
ここでは「robots.txtテスター」を活用し、robots.txtを確認する方法について解説していきます。
参考ページ : SearchConsoleヘルプ
構文の確認
構文の確認とは、robots.txtファイルの記載内容が文法的に正しいかを判断するための方法です。以下の方法にて構文確認をおこなえます。
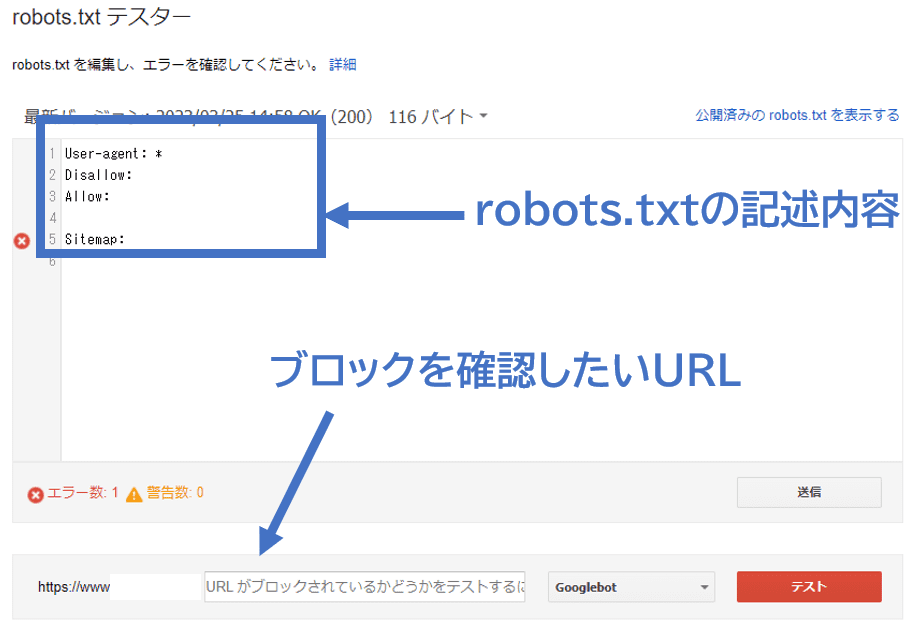
- 「robots.txtテスター」にアクセスする
- 画面下部のURL入力欄に該当するURLパスを入力し「テスト」をクリックする
- テスト結果が表示される
テストを行う前に、自社サイトが正しく連携されているかを確認してください。仮に自社サイトが反映しない場合には、robots.txtファイルが正しく設置されていません。そのため、再度robots.txtファイルを設置してからテストをおこないます。
構文の修正
「robots.txtテスター」でテスト結果を確認したら、エラーが発生していないかを確認します。
仮にエラーが発生している場合には、まずは「robots.txtテスター」内で修正をおこないます。エラー箇所をクリックし直接文字を入力すると、構文が変更されます。
再度間違った構文となった場合にはエラーが発生するため、エラーがなくなるまで内容を修正することが大切です。
ただし「robots.txtテスター」で修正を行ったとしても、実際のrobots.txtファイルが変更されるわけではありません。そのためエラー内容を確認後、実際のファイルを修正します。
再度、前述の流れでテストを行ない、エラーが発生しなければ確認完了となります。
robots.txtを設定する際の注意点
robots.txtは記述項目に沿って入力するだけとなり、比較的簡単な設定といえます。ただし以下の項目は間違いやすい内容となるため、活用する際は目的がズレないように注意が必要です。
- インデックス拒否の目的で使用しない
- 重複コンテンツ対策の目的で使用しない
- ユーザーのアクセス制限にはならない
- txtの更新
各々、解説していきます。
インデックス拒否の目的で使用しない
よくある間違いとして多いことが、インデックスの拒否を目的としたrobots.txtの使用です。
robots.txtはあくまでクロールを拒否する設定のため、インデックス拒否ではnoindexを使用しなければいけません。一見同じような効果に感じられますが、誤った使い方をすると「サイトの説明文がない状態で検索結果に表示される」など、エラーが発生するため注意します。
サイト全体の評価にも影響を及ぼすため、本来の目的に応じた設定を行うことが重要です。
重複コンテンツ対策の目的で使用しない
前述の「インデックス拒否」と同じ理由ですが、重複コンテンツ対策としてrobots.txtを使用することもやめましょう。
サイトのコンテンツ量が増加すると、どうしても重複コンテンツが発生しやすくなります。そのためクロールを拒否することで重複を解消できると考えやすいですが、インデックスされた時点で検索エンジンからは重複コンテンツと認識されます。
robots.txtでは完全な対処ができないため、重複コンテンツでは「noindex」や「URLの正規化」によって対策します。
ユーザーのアクセス制限にはならない
robots.txtの間違った活用目的が、ユーザーのアクセス制限です。インデックスと同じように、検索エンジンから完全に排除されると考えられた際に間違いやすいといえます。
しかしrobots.txtではユーザーのアクセスを制限する効果はありません。そのためインターネット上にURLが記載されていれば、クロールを拒否した場合でもアクセスは可能となります。
アクセス制限を行うには別途の設定が必要となるため、得られる効果を間違えないように注意してください。
robots.txtの更新
WEBサイトをリニューアルしたり、ページのURLが変更された場合、robots.txtを適切に更新する必要があります。これは、検索エンジンに正確な情報を提供するためだけでなくWEBサイトのSEOにも影響を与えます。
具体的にはリニューアル前のページが旧URLで検索エンジンにインデックスされていた場合、新しいURLにリダイレクトするための301リダイレクトを設定し、同時にrobots.txtにも新しいURLを反映します。これにより、検索エンジンが新しいページを正しくクロールし、WEBサイトのSEOに悪影響を与えることもありません。
また、ページの削除や追加があった場合にも、同様にrobots.txtの設定を変更してください。
robots.txtのよくある質問
ここでは、robots.txtについてよく寄せられる質問と答えをお伝えします。
Q: robots.txtはどこに配置する必要がありますか?
Answer)robots.txtは、WEBサイトのルートディレクトリに配置します。ルートディレクトリとは、WEBサイトの最上位階層にあるディレクトリのことを指します。ルートディレクトリについての詳細は下記のページを参考にしてください。
参考ページ : SEOに強いディレクトリ構造の作り方について解説
また、robots.txtをルートディレクトリ以外に配置することも可能ですが、検索エンジンが正しくクロールすることができなくなるため、推奨しません。
Q: robots.txtを間違って設定するとどのような問題が起きますか?
Answer)robots.txtを間違って設定すると検索エンジンがWEBサイトのページをクロールできなくなる場合があります。たとえば、誤ったディレクティブを指定した場合、検索エンジンがクロールを拒否するようになるため、SEOのランキングの低下などの事態を引き起こします。
Q: robots.txtはSEOに影響を与えますか?
Answer)適切にrobots.txtを設定すれば、検索エンジンに対してクロールする必要がないページを指定できるため、SEOにプラスの影響を与えることがあります。一方、robots.txtを不適切に設定するとSEOのランキング低下を招く可能性があります。
Q: robots.txtはページを非表示にするためのものですか?
Answer)robots.txtは検索エンジンに対してクロールを禁止するページやディレクトリなどを指定するためのものです。そのため、ページを非表示する目的では使用できません。ページを非表示にするにはrobots.txtではなく、メタタグのnofollow属性などを使用する必要があります。
まとめ
本記事ではrobots.txtについて、基本知識から記述方法、そして具体的な設定方法を解説してきました。noindexと間違えやすい設定ですが、インデックスの拒否とクロールの拒否では効果面が大きく異なるため注意をしましょう。また本来得られる効果が失われてしまう可能性もあるため、あくまで目的に合わせて使用することが重要となります。robots.txtの設定自体は簡単に行えるため、本記事の書き方や設定方法を参考にぜひ実践していきましょう。

この記事の監修者

日本大学法学部卒業、広告代理店で12年間働いている間、SEOと出会い、SEO草創期からSEO研究を始める。SEOを独学で研究し100以上のサイトで実験と検証を繰り返しました。そのノウハウを元に起業し現在、11期目。営業、SEOコンサル、WEB解析(Googleアナリティクス個人認定資格GAIQ保持)コーディング、サイト制作となんでもこなす。会社としては今まで2000以上のサイトのSEO対策を手掛けてきました。



















