
JavaScript SEOの基本とユーザーエクスペリエンスの向上のための施策
 Javascriptを使用してWEBサイトやWEBアプリを構築している場合、コンテンツをユーザーが見つけやすくする必要があります。通常のWEBサイトであればコーダーがディレクターと連携して作成することになりますが、Javascript SEOでは特有のSEOの知見が必要となるため、事前に抑えるべきポイントを共有しなければなりません。
Javascriptを使用してWEBサイトやWEBアプリを構築している場合、コンテンツをユーザーが見つけやすくする必要があります。通常のWEBサイトであればコーダーがディレクターと連携して作成することになりますが、Javascript SEOでは特有のSEOの知見が必要となるため、事前に抑えるべきポイントを共有しなければなりません。
Javascript SEOでは通常のWEBサイトとはレンダリングという処理を挟む分、難易度が高くなります。Javascriptとしては正常に動作していてもSEOを意識した作りになっていなければGoogle検索に引っかからないことすらあり得ます。これはサーバーサイドレンダリングではなく、クライアントサイドでレンダリングされることに起因します。
 特にSPA(シングルページアプリ)ではこのことを踏まえたうえでJavascript SEOを実践することが重要になってきます。
特にSPA(シングルページアプリ)ではこのことを踏まえたうえでJavascript SEOを実践することが重要になってきます。

GoogleがJavaScriptを処理する仕組み
Googleは、JavaScript ベースのウェブアプリを3つのフェーズで処理します。
- クロール
- レンダリング
- インデックス登録
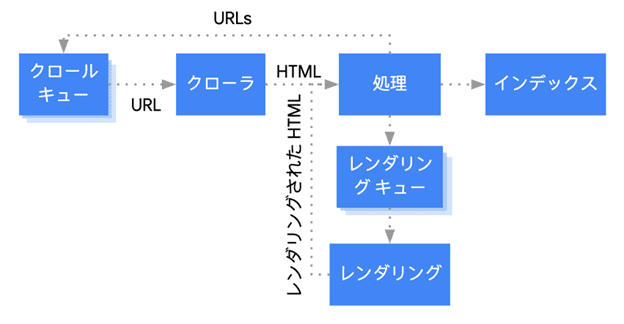
画像引用:JavaScript SEO の基本を理解する(Google検索セントラル)
通常のWEBサイトであればGoogle botはクロールとインデックス登録をしてからランキングをすることになるので、Javascriptで処理する場合はレンダリングという処理が1つ増えることになります。
通常のWEBサイトではサーバーサイドでレンダリングされるため、URLのクロールとサイト内の解析は問題なくできますが、Javascriptに依存した一部のサイトではクライアントサイドでレンダリングすることになるため、GoogleがJavascriptによって生成されるコンテンツを参照するまでコンテンツが含まれておりません。
つまり、従来のWEBサイトとJavascriptによるWEBサイト(WEBアプリ)ではレンダリングをサーバーサイドでおこなうか、ユーザーサイド(クライアントサイド)でおこなうのかが異なるため、Javascriptの記述次第ではGoogleがWEBサイトを正しく理解できないことが考えられます。
Javascriptを使ってWEBサイトやWEBアプリを作成し、SEOを実施したい場合、Javascriptとしては正しい記述であっても、Google botを意識した記述をしていないとGoogleに認知すらされないことがあります。そのため、Javascript SEOでは従来のSEO内部対策の知識のほか、コーディングの知識も必要になってきます。
GoogleでJavascript SEOを実践する方法
Javascript SEOであっても、SEO対策という括りでは従来のWEBサイトのSEO対策と同様のことをおこなうことになります。ただし、Javascriptではコーディング方法によってコードとして正しく動作することはあっても、Googleに正しく伝えることができないことがありますので注意が必要です。
特に注意すべきJavascript SEOには次のようなものがあります。
- タイトルとdiscription
- 互換性のあるコーディング
- HTTPステータス
- History APIの使用
- canonicalの設定
独自のタイトルとdiscriptionを持つページを作成する
SEO対策ではタイトル設定は非常に重要であり、費用対効果の高い施策として知られています。タイトルタグはすべてのページに設定する必要があり、かつ、他のページと被ってはいけないというルールがあります。また、メタディスクリプションを付けることでユーザーが目的のサイトを見つけやすくなります。
タイトルとメタディスクリプションはどちらもページ内容を端的に表す必要があり、特にタイトルと内容に違いが大きい場合には検索順位に悪影響を及ぼす可能性が高いため、ユーザーの検索意図を考慮したうえで、タイトルと中身を一致させるようにしてください。
どちらもJavascriptで設定可能な項目ですので、未実装の場合にはすぐに対応が必要です。
互換性のあるコーディング
Javascriptは急速に進化している言語であり、ブラウザからは多くのAPIが提供されています。そのため、GoogleがサポートするAPIとJavascriptの機能が完全に一致することはありません。ブラウザ側がAPIで足りない機能を検出するためには、差分配信とポリフィル(最近の機能をサポートしていない古いブラウザでも動作するためのJavascriptコード)の利用が必要です。
通常のサイト制作では考慮しないことが多い点ですが、Javascript SEOを実施する場合には互換性のあるコーディングをするかどうかでGoogleがページを認識するかどうかに関わってきますので、互換性は強く意識した制作が求められます。
正しいHTTPステータスコードの使用
Google bot は、ページをクロールする際に問題が発生したかどうかを確認するために、HTTP ステータス コードを使用します。
代表的なステータスコードには次のようなものがあります。
| HTTPステータスコード | Googleへの影響 |
| 200(success) | アクセスに成功したため、インデックスに登録される可能性があります。 |
| 301(moved permanently) | 恒久的なリダイレクトを意味します。リダイレクト先が正規のページであるという強い意味を持ちます。 |
| 302(found) | 一時的なリダイレクトを意味します。リダイレクト先が正規のページであるという弱い意味を持ちます。 |
| 404(not found) | ページが見つからないため、新規であればインデックスに登録されることはなく、過去に登録されていた場合にはインデックス削除の対象になります。 |
| 503(service unavailable) | サーバーエラーのため、登録されているURLはインデックス削除の対象となります。 |
HTTPステータスコードを正しく使うことでインデックス対象やインデックスされるかどうかに関わってくるため、検索を意識してJavascript SEOをおこなう場合には対処が必要です。しかし、SPA(シングルページアプリ)の場合、HTTPステータスコードを使用できないことがあります。
このような場合には、ソフト404エラーを回避するためには、次のいずれかの実施をしてください。
- サーバーが404HTTPステータスコードを返すURLにリダイレクトするJavaScriptを使用する
- JavaScriptを使ってエラーページに<meta name=”robots” content=”noindex”>を追加する
リダイレクトを行う場合のサンプルコード
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
window.location.href = ‘/not-found’; // redirect to 404 page on the server.
}
})
noindexタグを使用する場合のサンプルコード
fetch(`/api/products/${productId}`)
.then(response => response.json())
.then(product => {
if(product.exists) {
showProductDetails(product); // shows the product information on the page
} else {
// this product does not exist, so this is an error page.
// Note: This example assumes there is no other robots meta tag present in the HTML.
const metaRobots = document.createElement(‘meta’);
metaRobots.name = ‘robots’;
metaRobots.content = ‘noindex’;
document.head.appendChild(metaRobots);
}
})
History APIを使用する
Googleがリンク先をクロールできるのは、href属性が設定されたアンカータグの要素のみです。SPA(シングルページアプリ)では#(ハッシュまたはフラグメント)を使って別ページのコンテンツを読み込むことが可能ですが、フラグメントを使ってもGoogleはURLを解析できません。
Javascript SEOではリンクをうまくGoogle botに伝えるために、アンカータグを使ったリンクを構築するようにしてください。
フラグメントを使った適切ではない例
<nav>
<ul>
<li><a href=”#/products”>Our products</a></li>
<li><a href=”#/services”>Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id=”placeholder”>
<p>Learn more about <a href=”#/products”>our products</a> and <a href=”#/services”>our services</p>
</div>
<script>
window.addEventListener(‘hashchange’, function goToPage() {
// this function loads different content based on the current URL fragment
const pageToLoad = window.location.hash.slice(1); // URL fragment
document.getElementById(‘placeholder’).innerHTML = load(pageToLoad);
});
</script>
History APIを実装した適切な例
<nav>
<ul>
<li><a href=”/products”>Our products</a></li>
<li><a href=”/services”>Our services</a></li>
</ul>
</nav>
<h1>Welcome to example.com!</h1>
<div id=”placeholder”>
<p>Learn more about <a href=”/products”>our products</a> and <a href=”/services”>our services</p>
</div>
<script>
function goToPage(event) {
event.preventDefault(); // stop the browser from navigating to the destination URL.
const hrefUrl = event.target.getAttribute(‘href’);
const pageToLoad = hrefUrl.slice(1); // remove the leading slash
document.getElementById(‘placeholder’).innerHTML = load(pageToLoad);
window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history.
}
// Enable client-side routing for all links on the page
document.querySelectorAll(‘a’).forEach(link => link.addEventListener(‘click’, goToPage));
</script>
canonicalの設定
canonicalは正規ページをGoogleに伝える重要な手法ですが、通常はJavascriptでの使用は推奨されません。しかし、Javascriptを使ってcanonical設定をすることは可能です。Javascriptを使った場合、レンダリング時に正規URLが取得されますので、このときに正しいURLのシグナルを伝えることができるようになります。
fetch(‘/api/cats/’ + id)
.then(function (response) { return response.json(); })
.then(function (cat) {
// creates a canonical link tag and dynamically builds the URL
// e.g. https://example.com/cats/simba
const linkTag = document.createElement(‘link’);
linkTag.setAttribute(‘rel’, ‘canonical’);
linkTag.href = ‘https://example.com/cats/’ + cat.urlFriendlyName;
document.head.appendChild(linkTag);
});
Javascript SEOでユーザーエクスペリエンスを高める方法
Javascriptであってもユーザーエクスペリエンスを意識する際の注意点は変わりませんが、Javascriptを使っている場合、通常のWEBサイトと同様に設定できるとは限りません。
Javascript SEOでユーザーエクスペリエンスを高めるには特に次のような点を意識するようにしてください。
- robots metaタグの使用
- 長期保存キャッシュの利用
- 構造化データ
- 正しいレンダリング
- 画像の遅延読み込み
- アクセシビリティを考慮した設計
robots metaタグの使用
robots metaタグを使うことで、Googleによるページのインデックス登録やリンクの参照を回避することができます。noindexやnofollowをmetaタグで設定することは比較的レアケースではありますが、敢えてGoogleに登録する必要がないページがあれば、API呼び出しでコンテンツが返されない場合、ページがインデックス登録されないようにJavascriptで設定することができます。
fetch(‘/api/products/’ + productId)
.then(function (response) { return response.json(); })
.then(function (apiResponse) {
if (apiResponse.isError) {
// get the robots meta tag
var metaRobots = document.querySelector(‘meta[name=”robots”]’);
// if there was no robots meta tag, add one
if (!metaRobots) {
metaRobots = document.createElement(‘meta’);
metaRobots.setAttribute(‘name’, ‘robots’);
document.head.appendChild(metaRobots);
}
// tell Google to exclude this page from the index
metaRobots.setAttribute(‘content’, ‘noindex’);
// display an error message to the user
errorMsg.textContent = ‘This product is no longer available’;
return;
}
// display product information
// …
});
長期保存キャッシュの利用
Google botはネットワークリクエストとリソース使用量を減らすために、積極的にキャッシュを利用しますが、WRS(WEBレンダリングシステム)はキャッシュヘッダーを無視することがあり、古いJavascriptやCSSを使ってしまう可能性があり得ます。
この問題を解決するためには、リソースのURLを変更し、コンテンツが変わるたびにユーザーに新しい情報をダウンロードするようにしなければならず、方法としてはフィンガープリント(個々のユーザーを判別する情報)またはバージョン番号をファイル名の一部にすることが挙げられます。
フィンガープリントまたはバージョン情報が含まれ、コンテンツが変更されることがないURLのリクエストに応答する場合は、レスポンスにCache-Control: max-age=31536000(31,536,000 秒⁼1年間)を追加してください。
構造化データを使用する
構造化データを生成する方法には、JavaScriptを使って構造化データを作成するか、サーバー側でレンダリングされた構造化データに情報を追加する方法があります。どちらの方法でも、ページのレンダリング時に構造化データが認識され、処理されます。
Javascriptを使って構造化データを使用する場合、JSON-LDを生成してページに挿入することになりますが、問題を避けるためにも必ずリッチリザルトテストを使って実装テストをしてください。
JavaScriptで構造化データを生成する例
fetch(‘https://api.example.com/recipes/123’)
.then(response => response.text())
.then(structuredDataText => {
const script = document.createElement(‘script’);
script.setAttribute(‘type’, ‘application/ld+json’);
script.textContent = structuredDataText;
document.head.appendChild(script);
});
正しいレンダリング
Google はレンダリングされたHTMLに表示されるコンテンツのみを認識できます。レンダリング後にGoogleがコンテンツを引き続き認識できるようにするには、リッチリザルトテストやURL検査ツールを使ってレンダリングされたHTMLを確認する必要があります。
レンダリングされたHTMLにコンテンツが正しく表示されない場合は、Googleはインデックスに登録できませんので、Javascript SEOでは正しくレンダリングされているかどうかを必ずチェックしてください。
例えば次のようなコーディングをすることで、Google はこのコンテンツをインデックスに登録することができるようになります。
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: ‘open’ });
}
connectedCallback() {
let p = document.createElement(‘p’);
p.innerHTML = ‘Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>’;
this.shadowRoot.appendChild(p);
}
}
window.customElements.define(‘my-component’, MyComponent);
</script>
<my-component>
<p>This is light DOM content. It’s projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
画像の遅延読み込み
画像があるとネットワークとパフォーマンスにかなりの負荷がかかることがあるため、ユーザーが画像を表示しようとしたときにだけ、画像を遅延読み込みする方法が推奨されています。重要でないコンテンツや非表示のコンテンツの読み込みを後回しにすることは「遅延読み込み」と呼ばれ、パフォーマンスやユーザーエクスペリエンスに関する推奨方法としてよく挙げられます。ただし、遅延読み込みが正しく実装されていないと、対象のコンテンツをGoogleが認識できなくなるおそれがあります。
Google がページのすべてのコンテンツを認識するようにするには、関連コンテンツがビューポートに表示されるときに読み込まれるように、次のような方法で遅延読み込みを実装する必要があります。
- 画像やiframeにネイティブ遅延読み込みを使用する
- IntersectionObserver APIとポリフィルを使用する
- ビューポートに表示されるデータのみを読み込むJavaScriptライブラリを使用する
アクセシビリティを考慮した設計
検索エンジンだけではなく、ユーザーも考慮してページ作成は当然ですが、Javascript SEOを意識してサイトを設計する際には、JavaScript 対応のブラウザを使用していないユーザーのニーズも考慮してください。
サイトのアクセシビリティをテストするには、JavaScript を無効にしたブラウザで閲覧するのがもっとも確実で簡単な方法です。テキストのみでサイトを表示すると、画像に埋め込まれたテキストのようにGoogleによるアクセスが困難な他のコンテンツの特定に役立ちます。
まとめ
SEOという観点では、通常のWEBサイトもJavascript SEOも変わりませんが、Javascriptではレンダリングという処理を挟むため、レンダリング対策が必要になってきます。また、コーディングとしては正しく動いてもSEOを意識するとなると特別な設定が必要になってくることがあるため、制作前に事前にインプットすべき内容が多い傾向にあります。特にSPA(シングルページアプリ)でのSEOでは対策できるポイントも制限されることになるため、レンダリングを意識したうえで要所を抑えた対策が求められます。

この記事の監修者

日本大学法学部卒業、広告代理店で12年間働いている間、SEOと出会い、SEO草創期からSEO研究を始める。SEOを独学で研究し100以上のサイトで実験と検証を繰り返しました。そのノウハウを元に起業し現在、11期目。営業、SEOコンサル、WEB解析(Googleアナリティクス個人認定資格GAIQ保持)コーディング、サイト制作となんでもこなす。会社としては今まで2000以上のサイトのSEO対策を手掛けてきました。


















