
インターネットアーカイブとは?SEOに役立つツールの活用法

Webサイトの過去の情報がわかれば、自社サイトのSEO対策に活かせます。そこで便利なツールが「Wayback Machine」です。Wayback Machineは、インターネットアーカイブが提供するWebアーカイブサービスです。
ツールを使いこなせば、過去のWebデータを効果的に分析しSEO対策を今以上に強化できます。競合サイトとの比較や検索上位サイトの分析は、SEO担当者にとって不可欠なスキルです。
 この記事では、Wayback Machineを中心としたインターネットアーカイブの使い方を詳しく解説し、SEO対策にどう活かせるかを具体的に紹介します。
この記事では、Wayback Machineを中心としたインターネットアーカイブの使い方を詳しく解説し、SEO対策にどう活かせるかを具体的に紹介します。


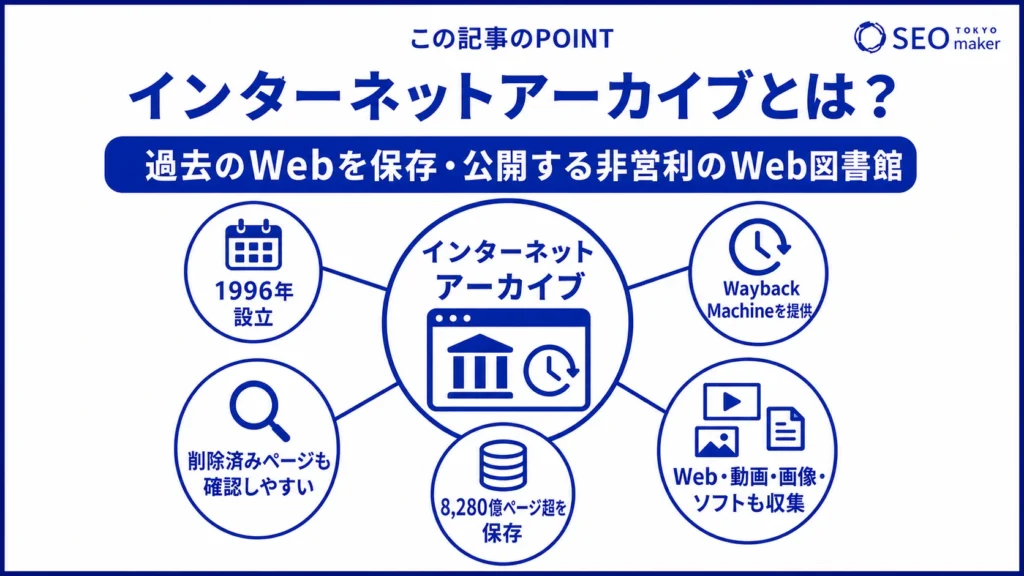
インターネットアーカイブとは
インターネットアーカイブは、デジタル情報を保存し過去の状態を確認できるサービスを運営している非営利団体です。1996年にアメリカの起業家であるブリュースター・ケール氏によって設立されました。団体の主なサービスは「Wayback Machine」であり、過去のWebサイトの情報や削除されたページを閲覧できます。
インターネットアーカイブの目的は、デジタル情報やデータを保存し、世界中の人々が無料で閲覧できることです。Web上の情報だけでなく、ソフトウェアや動画コンテンツなどのデジタルデータも保存しています。現時点で保存されているデータ量は8,280億ページを超えており、Web図書館といえます。
Wayback MachineのSEOへの活用法
Wayback Machineの保存データを使用して、SEO対策に活用できます。以下に具体的な活用法を挙げ、それぞれの効果について詳しく説明します。
サイト順位が下がった原因を上位サイトから調査する
Wayback Machineを活用して上位のWebサイトを調査すると、自社サイトの改善策のヒントを得られます。Googleのアルゴリズムアップデートが行われるたびに検索順位が変動しても、対応策に悩むことが減るでしょう。
Wayback Machineは、過去のWebサイトの内容を記録しています。保存してある過去のサイトと現状を比較し、どの要素が追加されて順位が変動したのかを特定できます。
自社サイトの順位が下がって競合サイトの順位が上がった場合、競合サイトの変更内容を分析し自社サイトの改善に活かしてください。
評価されやすいトレンドを分析する
検索エンジンに評価されるトレンドについて、検索上位のサイトを分析できます。
アルゴリズムのアップデートによるトレンドを分析するには、評価されている上位サイトを確認します。たとえば、Googleが権威性や専門性を重視するアップデートを行った場合、評価された上位サイトがどのような信頼できるコンテンツが含まれているのかをチェックしましょう。
Webサイトの見た目の変化と変更された時期を特定すれば、トレンドの内容や評価された要因を分析できます。
過去のWebページを残して復元できる
ページの構成を変更しても元に戻す可能性がある場合、Wayback Machineで保存した以前のWebページに後からアクセスできます。
たとえば、あるページの構成を変更して検索順位が向上した場合、変更点がSEO対策にどのような影響を与えたか分析可能です。Wayback Machineで過去の構成を保存しておくことで「どこを変えたことで評価が上がったのか」を具体的に確認でき、他のページにも応用できるからです。
検索順位が下がってしまった場合や削除したページが後で必要になる場合でも、元のページを復元し再利用できます。
中古ドメインの運用履歴を確認できる
中古ドメインの活用は、検索エンジンに迅速に評価される有効な手段の1つです。しかし以前にどのようなサイトであったか確認せずに利用することはリスクを伴うため、ドメインの過去の運用履歴を確認しなくてはいけません。
中古ドメインはすでに利用履歴があるため、ドメインパワーが強くSEO対策の成果を早く上げやすいという利点があります。しかし、以下のマイナスの影響を及ぼす可能性があります。
- 過去にGoogleからペナルティを受けている
- リダイレクトが極端に多い
- スパムリンクが多い
中古ドメインの活用は、Wayback Machineを使用し過去の運用履歴を詳しく調査しましょう。
URL構造の変化を確認できる
Wayback Machineは、リダイレクト履歴やURLパターンの移り変わりの把握など、過去のURL構造の変化を確認できます。
保存されたデータは、Webサイトの見た目やコンテンツだけでなく、過去のURLを含みます。たとえば、特定のページがリダイレクトされた時期や、新しいURLが使われた時期が特定可能です。リダイレクト設定が適切に行われているかを確認することで、リンクジュースの損失も防げます。
URLはクローラーのインデックス作成に必要であり、間接的にSEO対策に影響しています。過去のURLの変化を確認することで、サイト評価の改善に役立てられるでしょう。
目的別のWayback Machineの使い方
Wayback Machineは、保存されたWebサイトのデータをさまざまな目的に活用できます。以下に、目的別の具体的な使い方を説明します。
過去のWebサイトを確認する
Wayback Machineで過去のWebサイトを確認する方法として、以下の3つがあります。
- URL検索
- キーワード検索
- 画像や動画などのコンテンツ検索
この方法で、効果的なSEO戦略を立てるためのデータを得られます。
URL検索
最も基本的な方法は、URLを使った検索です。以下の手順に従って操作を行います。
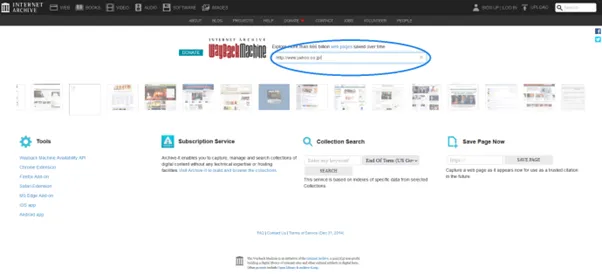
Wayback Machineの検索窓にWebサイトのURLを入力し、エンターキーを押します。
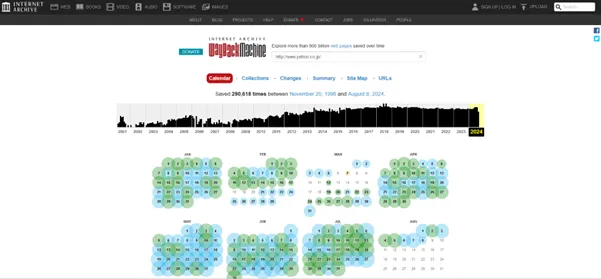
検索結果としてカレンダーが表示され、アーカイブされた日付に青や緑の丸が付きます。色のついた日付をクリックすることで、その日のWebサイトの状態を確認できます。
キーワード検索
キーワードを使って過去のWebサイトを検索することも可能です。キーワード検索は、特定のテーマや内容に関連するサイトを探す際に有効な方法です。
Wayback Machineの検索窓に、キーワードを入力します。
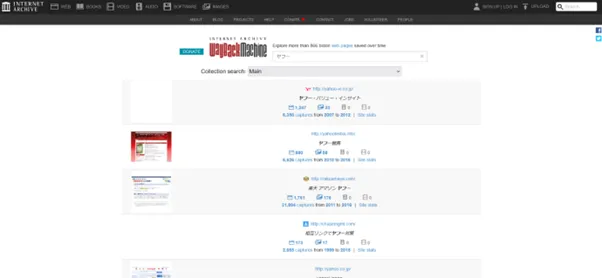
関連するWebサイトの一覧が表示されます。この中から目的のサイトを選び、カレンダー表示に移動して過去のデータを確認します。
画像や動画などのコンテンツの検索
Wayback Machineは画像や動画などもアーカイブしているため、過去のコンテンツを確認できます。
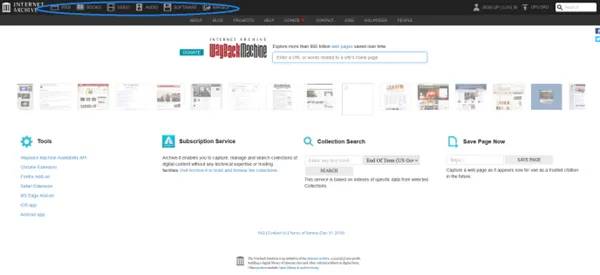
Wayback Machineのページ上部に並んでいるアイコンから「Images」や「Movies」などのカテゴリを選択します。
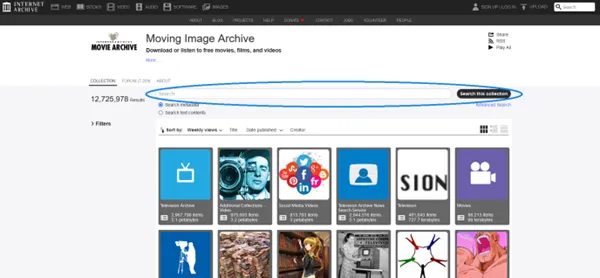
検索窓に対象の画像や動画に関連するキーワードを入力し、実行します。
Wayback Machineは、URL、キーワード、画像や動画などのコンテンツから過去のWebサイトを検索できます。検索結果を活用することで、過去のデータから効果的なSEO戦略を立てられます。
サイトのデータを保存する(手動、自動)
Webサイトのデータを保存することで、将来的な分析や比較を行う際に役立ちます。Wayback Machineには「手動保存」と「自動保存」の2つの方法があります。それぞれの手順を詳しく解説します。
手動保存
手動でデータを保存する方法は、自分のタイミングで確実にデータを保存したい場合に最適です。以下の手順に従って操作を行います。
Wayback Machineにアクセスします。
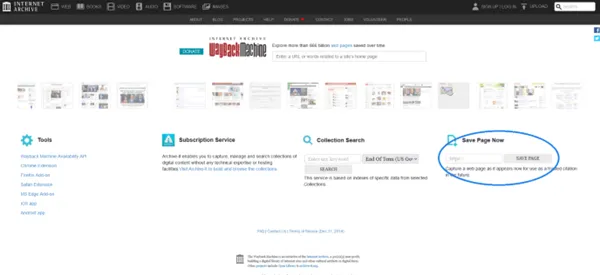
トップページ右下にある「Save Page Now」の項目に保存したいページのURLを入力し、「SAVE PAGE」ボタンをクリックします。
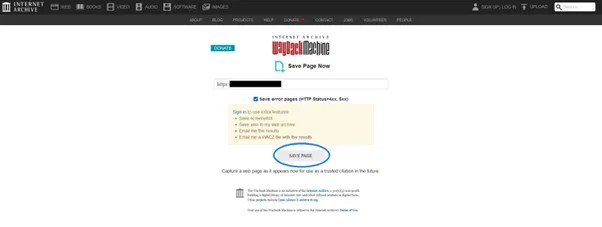
確認画面の内容を確認し、「SAVE PAGE」ボタンをクリックします。
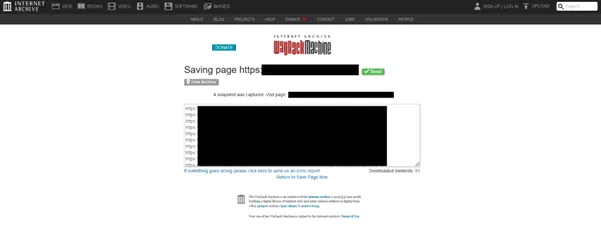
保存処理が開始され、「Page save [URL] Done!」と表示されれば登録完了です。保存処理は1分程度で完了します。
自動保存
Wayback Machineには、Webサイトを自動的にキャッシュする機能もあります。あらかじめ設定する必要はなく、定期的にデータを収集して保存します。しかし、自動保存のタイミングは不明確であり、必ずしも必要な時期に保存されるとは限りません。
手間をかけずに自動でデータが保存されるため、長期的な移り変わりを把握しやすいです。一方で保存されるタイミングが不確実であるため、特定のタイミングのデータを確実に保存したい場合には向きません。
Wayback Machineを活用してWebサイトのデータを保存する方法には、手動保存と自動保存があります。手動保存は、特定のタイミングで確実にデータを保存したい場合に適しています。一方、自動保存は手間をかけずに定期的にデータを更新したい場合に便利です。手動保存と自動保存を使い分け、効果的にWebサイトのデータを管理しましょう。
保存されているデータを削除する
Wayback Machineに保存されている過去のデータが意図せず公開されている場合、そのデータを削除する必要があります。
Wayback Machineに保存されている過去のWebページを削除する場合、インターネットアーカイブに直接連絡しなくてはいけません。公式メールアドレスは「info@archive.org」です。依頼を行う際には、以下の情報を含めるようにしましょう。
- 削除したいページのURL
- 運営者であることの証明
メールを送信した後、インターネットアーカイブのチームが依頼内容を確認し、適切な対応を行います。処理に時間がかかる場合もありますが、削除が完了すると通知が届きます。
クローラーのアクセスを制限する
Webサイトの運営方針によっては、Wayback MachineなどのクローラーによるWebサイトのキャッシュを制限したいこともあります。
まず、検索エンジンのクローラーに対してアクセス許可や拒否の指示を与えるためのファイル「robots.txt」を作成します。robots.txtファイルには以下のコードを記述します。
User-agent: ia_archiver
Disallow: /
このコードの意味は、クローラー「ia_archiver」に対して、サイト全体のクロールを禁止するというものです。作成したrobots.txtファイルをWebサーバーのトップディレクトリにアップロードします。
この設定を行うことで、Wayback Machineのクローラーは指定されたWebサイトのページをキャッシュしなくなります。「過去のデータはそのままで良いが、今後はWebサイトのキャッシュを取られたくない」という場合、クローラーのアクセスを制限することが有効です。
この方法は今後のクローリングを制限するものであり、既にWayback Machineに保存されているデータを削除するものではありません。既存のデータを削除したい場合は、別途削除依頼を行う必要があります。
競合サイトを分析する
Wayback Machineで競合サイトの過去と現在の変化を調べ、SEO対策を行うための分析が可能です。
Wayback Machineには「Changes」という便利な機能があり、この機能を使うことで競合サイトの過去と現在を比較できます。この機能では、削除された部分は黄色、追加された部分は青色で表示されるため、競合サイトがどのように変更されているかを一目で確認できます。
Wayback Machineの検索窓に確認したいWebサイトのURLを入力し、エンターキーを押します。
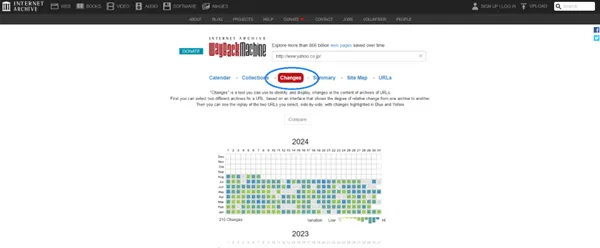
URLボックスの下にある「Changes」ボタンをクリックします。上図のとおり、Wayback Machineが撮った複数のスクリーンショットのカレンダービューが表示されます。比較したい2つの日付を選択し「Compare」をクリックします。
2つの保存されたサイトが表示され、変更点が黄色と青色でハイライト表示されます。
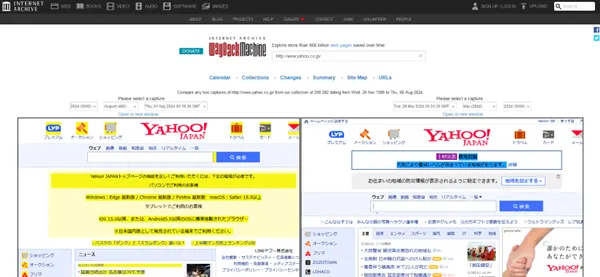
Wayback Machineの「Changes」機能は、競合サイトだけでなく自社サイトの過去と現在を比較する際にも非常に有効です。施策実施前と実施後のページ状況を比較分析することで、削除された部分や追加された部分が一目でわかるため、競合サイトの戦略を把握し、自社サイトの改善に役立てられます。
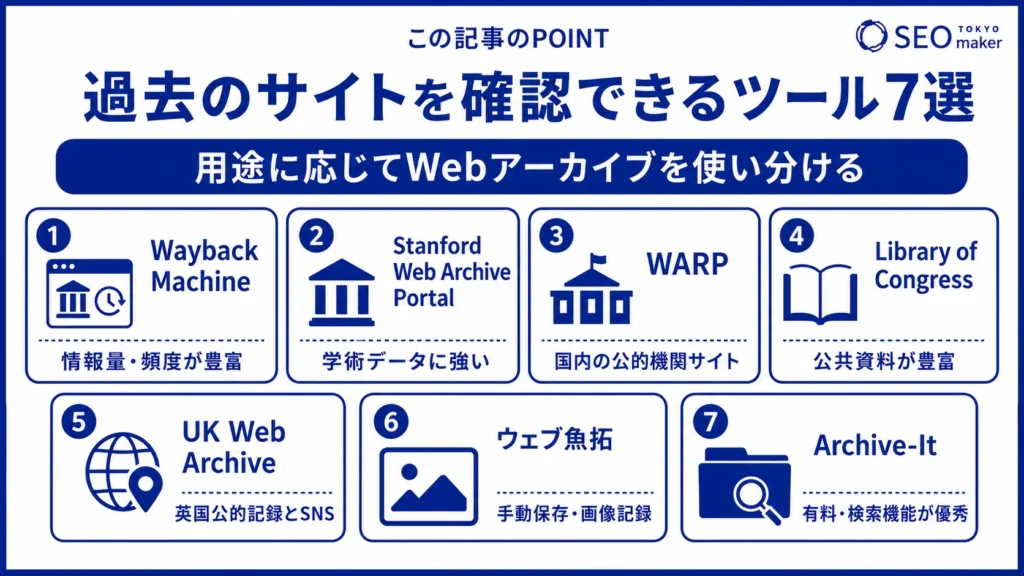
過去のサイトを確認できるツール6選
過去サイトをチェックするなら、ツールの利用が便利です。ここで紹介するツールはブラウザでアクセスできるので、対応OSは問いません。厳選した6選を、詳しく説明します。
1.Wayback Machine(アメリカ)
Wayback Machineは、アメリカの非営利団体である「インターネットアーカイブ」が提供するWebアーカイブサービスです。
| URL | https://web.archive.org/ |
| 運営者 | インターネットアーカイブ |
| 使用料 | 無料 |
| 特徴 | ・情報量が豊富
・アーカイブコンテンツ(Web、動画、電子書籍、画像、音楽など) ・クロール頻度が高い |
世界中のWebページを保存しており、無料で利用できてアカウント登録も不要です。
簡単な操作で、過去のWebサイトの状態を即座に確認できます。クロール頻度が非常に高く、保存されているWebページの数も膨大です。2024年月時点で、8,660億ページがアーカイブされています。保存ページ数は、他のツールと比べて圧倒的です。Webページだけでなく、PDFや動画などさまざまなデジタルコンテンツを保存しています。
Wayback Machineは高いクロール頻度と膨大な保存データがあり、過去のWebページを詳細に調査するのに最適なツールの1つです。
2.Stanford Web Archive Portal(アメリカ)
Stanford Web Archive Portal(SWAP)は、アメリカのスタンフォード大学が運営するWebアーカイブサービスです。
| URL | https://swap.stanford.edu/was/ |
| 運営者 | スタンフォード大学 |
| 使用料 | 無料 |
| 特徴 | ・学術データを含む
・Wayback Machineとインターフェースが似ているため使いやすい |
学術研究を目的とした多くのWebページを保存・提供しています。使いやすさとデザインがWayback Machineと類似しているため、利用経験のある方にとっては違和感なく使用できます。
Stanford Web Archive Portalは無料で利用できます。アカウント登録なども不要で、誰でも簡単にアクセスできるのが特徴です。
スタンフォード大学が運営しているため、データの信頼性と品質は非常に高いです。学術的な用途に特化している部分もあり、研究者や専門家にとって価値のあるツールといえます。
3.WARP(日本)
WARPは、国立国会図書館が運営するインターネット資料収集保存事業の一環で、過去のWebサイトを確認できるツールです。
| URL | https://warp.ndl.go.jp/ |
| 運営者 | 国立国会図書館 |
| 使用料 | 無料 |
| 特徴 | 公的機関のWebサイトを多く保存 |
日本国内のサイトに限定されており、国の機関や地方自治体、独立行政法人、国公立大学などの公的機関のWebサイトを収集しています。国立国会図書館が運営しているため、登録や利用に関して特別な費用は発生しません。
WARPは、民間のWebサイトも許可を得て収集されています。URL、タイトル、公開社名、書誌IDなど、複数の検索オプションが用意されているため、目的の情報に迅速にアクセスできます。
4.Library of Congress(アメリカ)
Library of Congressは、アメリカ議会図書館が運営するWebアーカイブサービスです。
| URL | https://www.loc.gov/ |
| 運営者 | アメリカ議会図書館 |
| 使用料 | 無料 |
| 特徴 | 学術的な資料や公共機関のデータが豊富 |
収集頻度はWebサイトによって異なり、週1回~四半期に1回です。収集されたWebサイトは、収集日から1年後に発信者の許可を得てWeb上で公開されます。数は多くありませんが、日本語のサイトも収集されています。
Library of CongressのWebアーカイブサービスは無料で利用できます。アカウント登録や特別な手続きも不要で、誰でも簡単にアクセスできるのが特徴です。
5.UK Web Archive(イギリス)
UK Web Archiveは、イギリスの大英図書館が運営するWebアーカイブサービスです。
| URL | https://www.webarchive.org.uk/ |
| 運営者 | イギリスの大英図書館 |
| 使用料 | 無料 |
| 特徴 | TwitterやYouTubeの情報も保存 |
イギリス政府や公的機関が発信する情報を中心に、TwitterやYouTubeの情報も「公的な記録」として保存しているのが特徴です。アカウント登録や特別な手続きは不要で、無料で誰でも簡単にアクセス可能です。
収集されたデータは、以下の4つの図書館に分散して保存されています。
- 英国図書館
- 英国図書館分館
- スコットランド国立図書館
- ウェールズ国立図書館
どこかの図書館でデータが消失しても、他の図書館のデータから自動的に復元されます。データの信頼性と安全性が高く多くのコンテンツを収集しているため、広範囲で情報収集と分析が可能です。
6.ウェブ魚拓(日本)
ウェブ魚拓は、株式会社アフィリティーが運営するWebページ保存サービスです。
| URL | https://megalodon.jp/ |
| 運営者 | 株式会社アフィリティー |
| 使用料 | 無料 |
| 特徴 | ・ユーザーが手動で保存する
・保存されたWebページは、画像データとして記録される |
ユーザーがWebサイトのURLを入力し、手動で保存します。ウェブ魚拓は無料で利用でき、登録や特別な手続きも不要です。
保存されたWebページは、画像データとして記録され内容を後から編集できないようになっていて、信頼性が高いです。著作権や名誉毀損に関するトラブルの際に、資料として引用できます。
日本語のインターフェースで操作が直感的に行えるため、初心者でも簡単に利用できます。ウェブ魚拓を拒否しているWebサイトも存在するため、全てのWebページが保存できるわけではありません。
7.Archive-It
Archive-Itは、専門的な知識がなくてもWebサイトや各種データを簡単に保存できる有料のアーカイブサービスです。

| URL | https://www.archive-it.org/ |
| 運営者 | インターネットアーカイブ |
| 使用料 | 有料 |
| 特徴 | 検索機能が優秀 |
インターネットアーカイブが運営しており、利用者が指定したWebサイトやページを保存し、後で見返したり全文検索を行ったりできます。検索機能の精度と速度が高く、効率的に情報を管理できます。
まとめ
Wayback MachineをはじめとするWebサイトを保存できるツールは、SEO対策に役立てるための有益な情報があります。ツールを適切に活用することで、検索順位の変動原因を特定したり、競合サイトの戦略を分析したりできます。過去のデータを有効に活用し、自社サイトの競争力をさらに向上させられるので、興味があれば使ってみてはいかがでしょうか。





















